


Analyze with AI
Get AI-powered insights from this Mad Devs article:
In a world where technology is advancing at an unprecedented pace, transfer learning stands out as one of the most promising and influential areas of machine learning. This approach to training models opens doors to faster and more efficient development, as well as flexibility in adapting to diverse tasks.
This article will introduce you to transfer learning, technical nuances, applications across various business sectors, and future prospects. Discover how transfer learning is shaping the modern world of technology and the opportunities it unveils for us all.
Transfer learning concept: Transferring knowledge from one model to another
The concept of Transfer learning was first proposed in 1995 by scientist Sebastian Thrun during his research in the field of artificial intelligence. At that time, researchers faced the problem that training each new model from scratch required immense computational resources and time. This issue became particularly acute with the growth of the complexity of models and the tasks they were meant to solve.
Transfer learning was the answer to this problem. It allowed the use of knowledge and experience gained in solving one task to be applied to another related task. This not only reduced the time and resources needed to train a new model but also enabled models to generalize knowledge across different domains and tasks.
The concept became a fundamental breakthrough in machine learning, as it opened new paths and training methods and allowed researchers and engineers to create more complex and powerful systems.
The role of transfer learning in improving LLM performance
Transfer learning has fundamentally revolutionized the landscape of Large Language Models, beginning with the Word2Vec era. Word2Vec focused primarily on local vector representations of words, employing algorithms like Skip-gram and Continuous Bag of Words (CBOW). However, these techniques lacked the capability to model long-term dependencies between words and failed to map intricate syntactic and semantic structures efficiently.
The introduction of BERT (Bidirectional Encoder Representations from Transformers) changed the game dramatically. BERT deploys attention mechanisms and bidirectional transformers to model contextual relationships between words in a sentence. This is achieved through Masked Language Modeling (MLM) and Next Sentence Prediction (NSP), enabling the model to learn from unstructured text data without explicit labeling. These methods render BERT optimal for tasks requiring deep contextual understanding and pave the way for effective transfer learning.
OpenAI's GPT-3 represents another evolutionary leap in this trajectory. The model utilizes a transformer architecture with 175 billion parameters, 100 times more than BERT. It also employs various attention mechanisms, including multi-head attention and positional encoding, to process different data types and tasks. This makes GPT-3 not only more accurate but also more versatile in transfer learning applications.
Special mention must be given to Google's T5 model. This model enhances the transfer learning concept by integrating it with other machine learning approaches. Unlike its predecessors, T5 employs a unified "text-to-text" approach, meaning all NLP tasks — text classification, translation, or question-answering systems — are framed as text transformation tasks.
Technically, T5 uses a transformer architecture with multi-head attention and positional encoding. What sets it apart, however, is its "supervised pre-training," where the model learns from pairs of input and output text. This enables T5 to efficiently transfer knowledge between various domains and tasks without requiring additional fine-tuning or specialized architectures for each specific task.
📖 By the way, we have an in-depth article, "Semi-Supervised Learning Explained: Techniques and Real-World Applications," that thoroughly explains different approaches in supervised and unsupervised learning, their combinations, and the opportunities this opens up for researchers and businesses. We recommend giving it a read!
The principle of transfer learning in the LLM
Technically, transfer learning is divided into two main stages: pre-training, where the model undergoes basic training, and fine-tuning, where the model is further trained for a specific task. The beauty of transfer learning for many lies in the fact that the first stage is not mandatory for many companies and tasks. They can take pre-trained models and fine-tune them for their specific needs. However, we will generally discuss both stages.
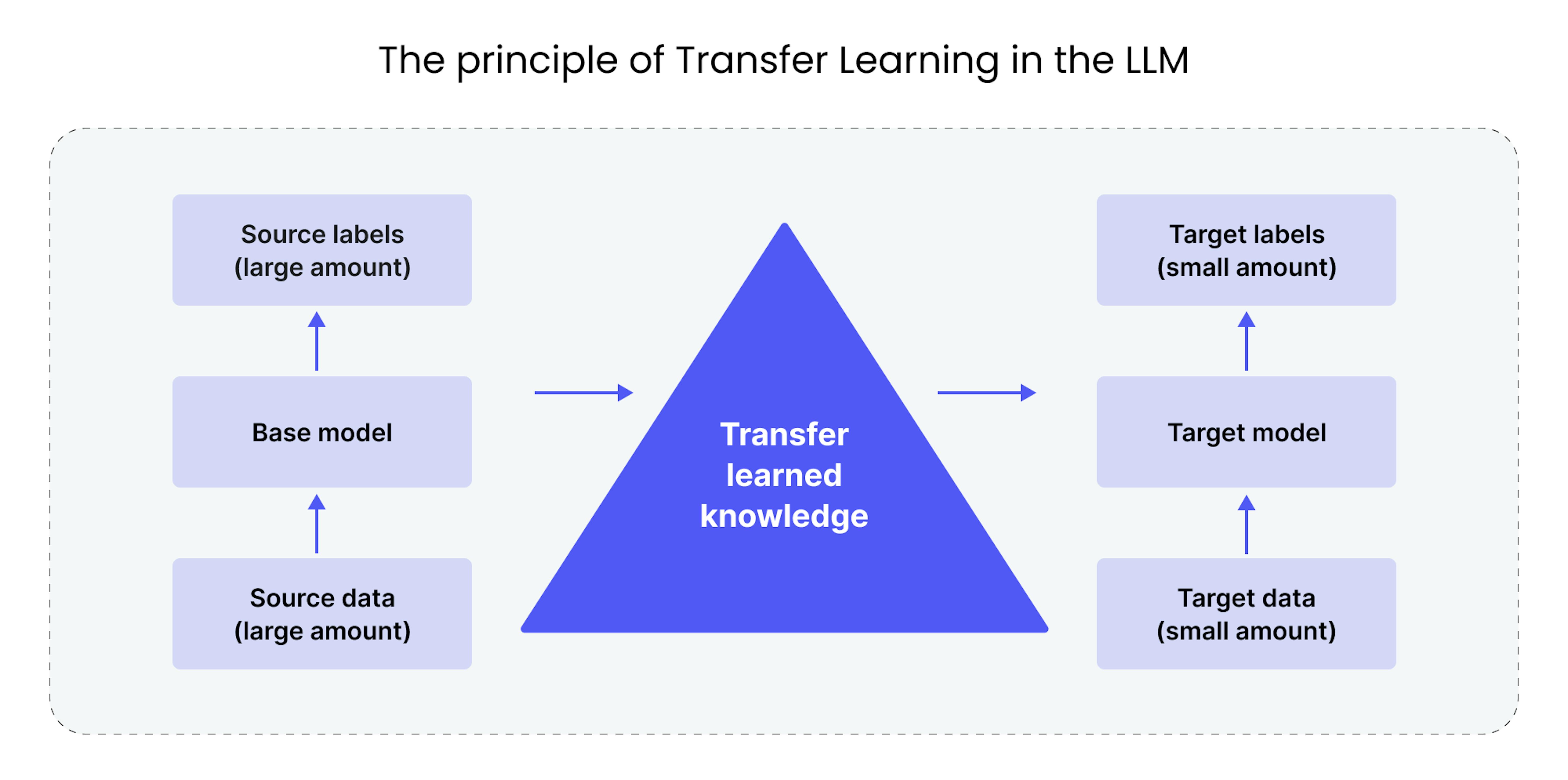
Pre-training on large data sets
Pre-training is the first and critically important stage for LLMs in the transfer learning process. At this stage, the model is trained on a vast corpus of textual data, including literature, news, web pages, and other sources. The process includes the following stages:
Tokenization and vectorization
Data conversion to machine-readable format is the initial data processing and preparation stage. In the case of text data, this process involves tokenization and vectorization. Tokenization involves splitting the text into individual words or tokens, and vectorization transforms these tokens into numerical vectors.
Choice of architecture
The next step is selecting the neural network architecture, a critically important phase that determines how efficiently the model will be able to process data and solve the given tasks. In the natural language processing (NLP) context, transformers have become the standard due to their ability to capture long-term dependencies in text. However, other architectures like RNNs or LSTMs might also be applicable depending on specific requirements and conditions.
Hyperparameter tuning
At this stage, key model parameters affecting its learning and performance are set. Learning rate specifies the pace at which the model adjusts its weights based on errors made in previous iterations. Batch size refers to the number of data samples processed in a single training iteration. The number of epochs indicates how often the model will iterate over the entire training dataset. These parameters are often selected through cross-validation, a statistical assessment method for optimizing model performance.
Optimization algorithms
This stage is critically important for the model's efficient learning. Optimization algorithms, such as Stochastic Gradient Descent (SGD) or Adam, not only adjust the model's weights but do so adaptively, considering the dynamics of the loss function. For instance, SGD updates the model's weights at each iteration with a small subset of the data, accelerating the learning process. Adam combines the best attributes of SGD and other algorithms for a more effective minimization of the loss function. Choosing the right optimization algorithm and its parameters can significantly impact the model's predictive quality and convergence speed.
Example:
Due to increasing accessibility and universal applicability, NLP is transforming the operational approaches of companies across every industry and size. We have an insightful article that delves into NLP Applications for Human Resource Management in detail.
Fine-tuning for a specific task
Fine-tuning is the second stage, where the model is adapted to a specific task. This stage includes:
Data preparation for the specific task
Preparing data for a particular task is the initial and crucial step. Data is collected and pre-processed to be highly relevant to the specific task at hand. In NLP tasks, this may include stop-word removal, the utilization of specialized lexicons, or more advanced technologies like TF-IDF vectorization.
Model adaptation
The model itself also undergoes architectural modifications to handle specialized tasks better.
This could mean replacing the last fully connected layer with a new one featuring an output neuron count that matches the number of classes in the new task. This layer is then fine-tuned on a new corresponding dataset, while the remaining layers may remain "frozen" to preserve features learned from larger datasets.
This can also include adding specialized layers for specific tasks like named entity recognition, sentiment analysis, etc. These new layers are also subsequently fine-tuned on task-specific data to make the model more efficient in solving any new issue.
Hyperparameter tuning for the specific task
Hyperparameter settings for specific tasks often differ from those for general training. Lower learning rates or smaller batch sizes may be needed for the model to adapt to new data more accurately.
Besides cross-validation, methods like differential evolution are often used for hyperparameter tuning in cases where the parameter space is continuous and complex, and particularly useful when the loss function's gradient is unknown or intractable.
Another method is population-based training, which dynamically adapts hyperparameters during training, allowing the model to converge faster to the optimal solution. This method is especially useful in tasks requiring quick adaptation to changing conditions, among many other methods depending on task-specificity.
Evaluation metrics
After retraining the model with the changes mentioned above, it's important to select the proper evaluation metrics. More specialized metrics can be used here rather than general ones like F1-score.
For instance, in text classification tasks, metrics like ROC AUC or Precision-Recall AUC may be used, which account for not just accuracy but also the model's ability to distinguish classes in imbalanced data scenarios. For machine translation tasks, relevant metrics include BLEU or TER, which evaluate translation quality at the level of individual words and phrases.
Thus, the choice of performance evaluation metrics must be adjusted to the specific task at hand to provide the most accurate and informative efficiency assessment.
Example:
The integration and utilization of machine learning models, notably through approaches like transfer learning, are becoming increasingly accessible to a broader spectrum of companies and an integral part of modern business. Alongside well-established DevOps practices, this necessitates the consistent implementation of MLOps methodologies. To delve into MLOps, refer to our article How to Increase Business Growth with MLOps.
Advantages of using transfer learning in LLMs
Applying transfer learning in LLMs brings many significant advantages, making it useful for businesses and research entities.
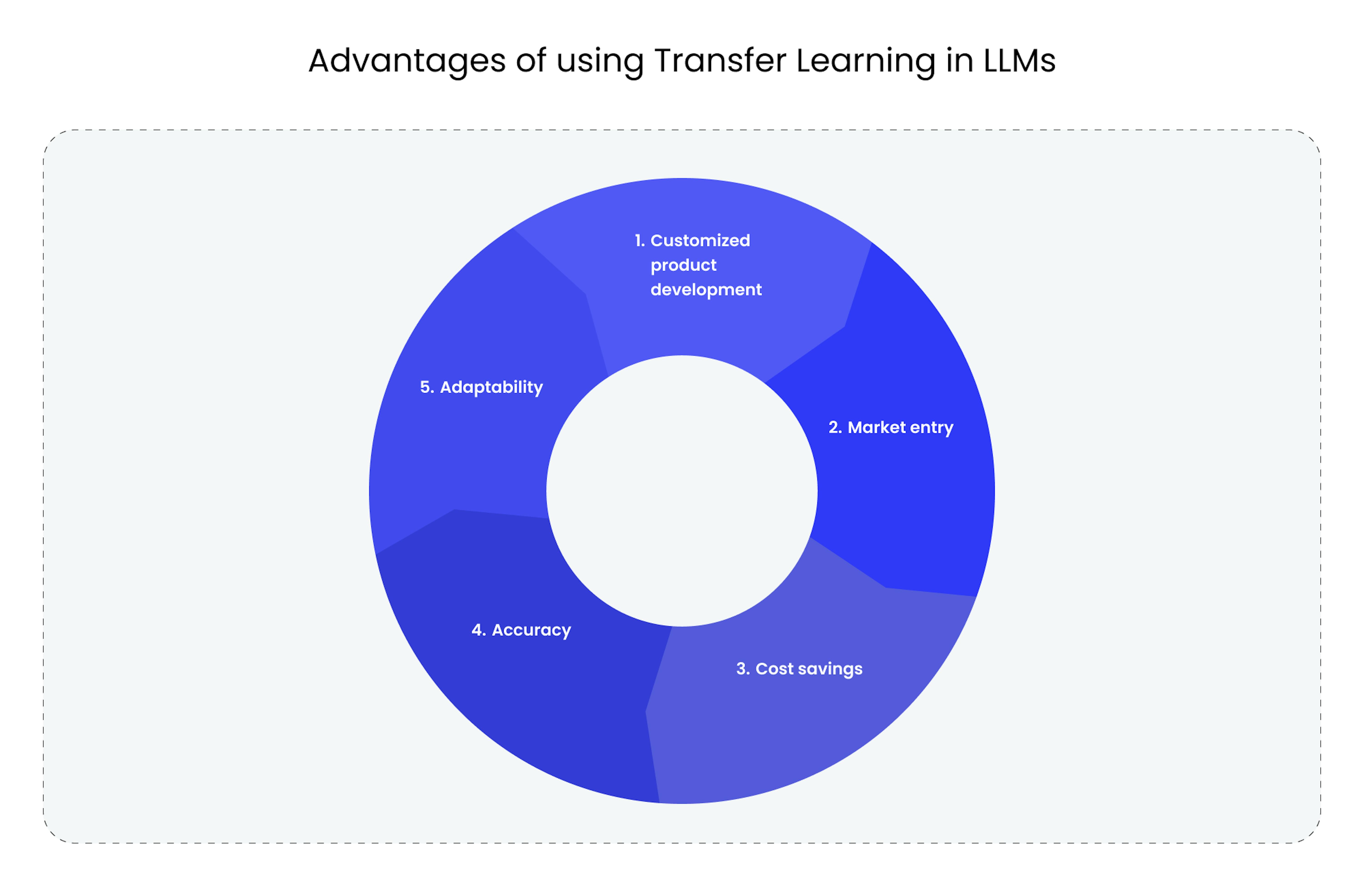
Customized product development
Utilizing transfer learning in LLMs allows for deep customization of algorithms for domain-specific tasks. This enables the injection of domain expertise into the model, ranging from sectors like healthcare to finance. As a result, each solution acquires unique, unattainable attributes through standard machine learning algorithms. This facilitates the deep integration of the products into existing business processes, reducing dependency on generic solutions and improving operational efficiency.
Market entry
Transfer learning in LLMs focuses on comprehensively understanding local nuances, from syntactic and grammatical elements to cultural intricacies and social cues. This minimizes language inaccuracies and, more crucially, lowers the risk of culturally inappropriate assumptions that could be offensive or unacceptable in a new region. Consequently, market entry becomes less risky and more predictable, allowing for a focus on strategic expansion rather than operational issues.
Cost savings
Traditional machine-learning approaches require substantial computational and time resources for training a model from scratch. Transfer learning can leverage pre-trained models, substantially reducing computational power and training time. This not only cuts down hardware and specialist man-hours but also speeds up the implementation of innovative projects. Freed resources can be reallocated to research and development rather than routine operations, turning the cost savings at the development stage into a strategic advantage for your business.
Accuracy
Standard machine learning models frequently encounter issues of overfitting or underfitting, compromising their effectiveness in real-world business scenarios. Transfer learning in LLMs significantly enhances prediction accuracy by using pre-collected extensive data sets and domain expertise. This allows for more effective customer personalization, business process adaptation, and decision-making systems. You gain a tool that accomplishes tasks with high accuracy, positively affecting client trust and, ultimately, profitability.
Adaptability
The industry is ever-changing, with new technologies, market demands, and customer preferences emerging. In such a dynamic environment, adaptability is a key factor. Transfer learning enables your LLMs to adapt rapidly to new conditions. Pre-trained models can be supplemented or modified for new tasks much more quickly than training models from scratch. This means your business can respond more swiftly to changes in market conditions or customer needs while maintaining high efficiency and competitiveness.
Challenges of transfer learning in LLMs
However, like any technological approach, it has its nuances and complexities. Understanding these aspects is critical for successfully implementing transfer learning in business processes.
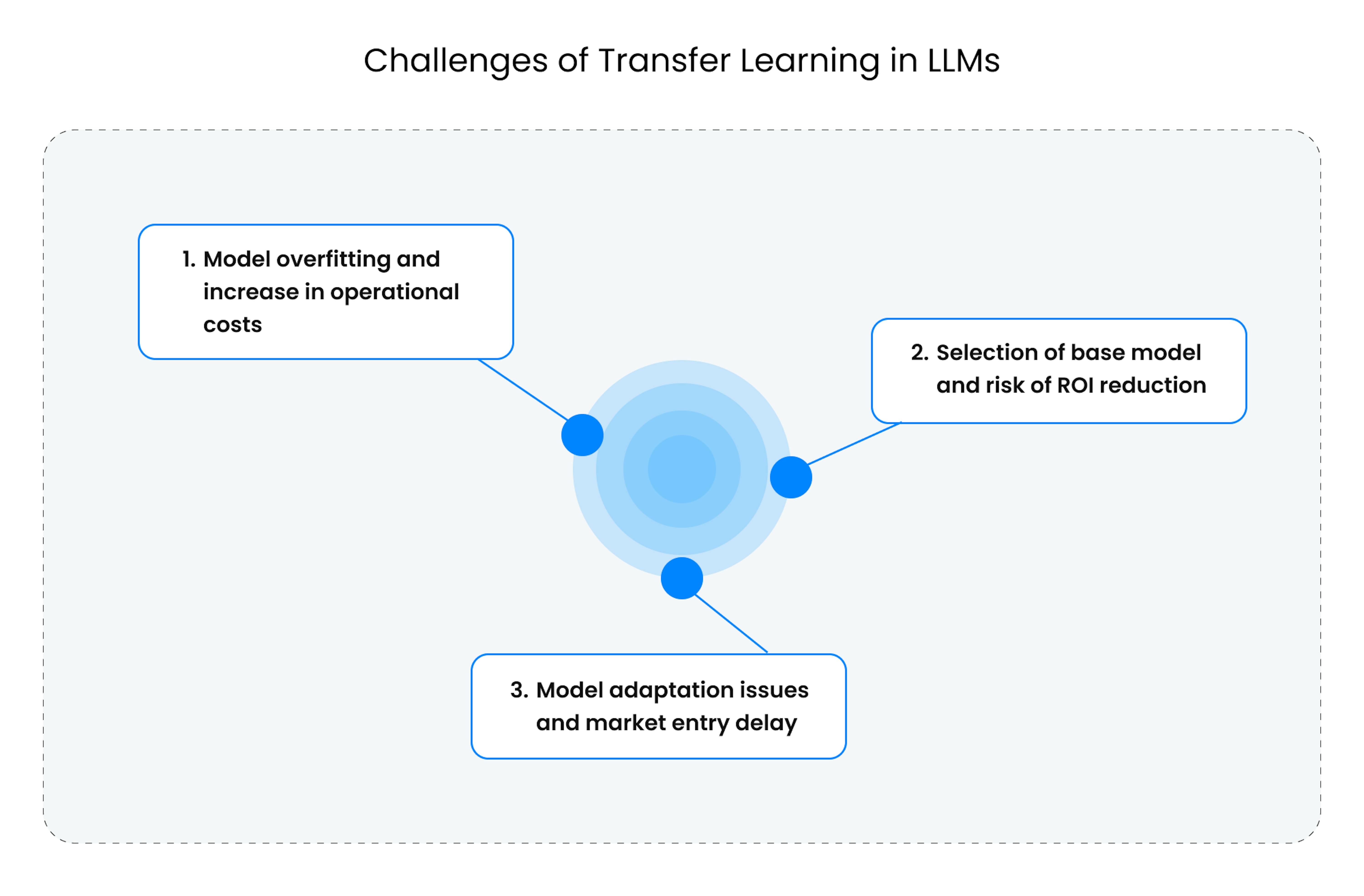
Model overfitting and increase in operational costs
Even with transfer learning, the risk of model overfitting is not fully eliminated. Overfitting occurs when an algorithm becomes too adapted to the initial dataset, losing its generalization ability. This threatens the model's flexibility and adaptability to new, real-world scenarios, leading to increased operational costs due to additional model adjustments or the development of a new solution.
Selection of base model and risk of ROI reduction
Choosing an unsuitable base model for pre-training can make knowledge transfer ineffective. If the model is initially trained on data that is significantly different from the target task, the process becomes not only slow but also ineffective, reducing ROI as the invested resources will not yield the expected return.
Model adaptation issues and market entry delay
Fine-tuning parameters and methods for adapting the model to a new task is a process that requires deep expertise. Incorrect adaptation can result in losing key model features, reducing effectiveness and accuracy. This increases the time the product enters the market, reducing its competitive advantage.
Implementing transfer learning in LLMs is a complex process that requires a deep understanding of both the technical aspects and the specifics of business tasks. However, with the right approach, it can be the key to creating flexible, powerful, and economically efficient AI solutions.
LLM applications with transfer learning in business
So, here, the specific applications are about the versatility and effectiveness of LLM with transfer learning in addressing various business needs that play critical roles.
Recommendation systems tailored to individual users. Recommendation systems work by analyzing large volumes of data about user behavior and interests in various contexts. This knowledge can be transferred to new, specific tasks, such as product recommendations in a particular category. Transfer learning allows the system to quickly adapt to this new data without training from scratch, making recommendations more accurate and personalized, increasing sales conversion, and improving customer relationships in business.
Automatic translations with context specifics. It enables automatic translators to transfer knowledge about language structures and cultural nuances from one language to another. This provides a more accurate and natural translation, adapting to the specific requirements of each language and context. This ability makes translations more understandable and trustworthy, enhancing international interaction and expanding global reach in business.
Sentiment analysis in social media. LLM with transfer learning can analyze amounts of data from various social networks to determine the overall sentiment or opinion on specific topics or products. Knowledge gained from one domain (e.g., product reviews) can be transferred to another domain (e.g., opinions on Twitter/X) to quickly adapt to new data. This can significantly assist businesses in making marketing, sales, or product development decisions.
Customer churn prediction. It also can analyze customer behavior and historical data to predict the likelihood of customer churn. Knowledge from one industry or market can be transferred to others to adapt to new conditions quickly. This can help businesses respond timely to changes in customer behavior and take measures to retain them.
Automated content analysis. Analyzing and categorizing large volumes of textual data, such as news articles, scientific publications, or patents, can be automated. Knowledge gained from studying one type of content can be transferred to another, providing rapid adaptation to new domains. This can be useful for research organizations, media companies, and government agencies in analyzing trends, competition, and regulatory changes.
Monitoring and managing complex systems. LLM with transfer learning can be applied to monitor and manage complex systems such as industrial production lines, energy networks, or transportation systems. Knowledge gained from one system or scenario can be transferred to optimize others, allowing for adaptation to a changing environment and ensuring high efficiency and reliability.
Fraud and security detection. It also can be used in financial and banking systems to detect fraudulent activities. Knowledge gained from analyzing previous fraud cases can be transferred to detect new, more complex schemes. This not only strengthens security but also reduces costs for monitoring and investigation.
Chatbots with the ability to learn from new data. Also, chatbots can use knowledge from previous interactions with users to process new requests. This allows them to adapt to new questions and complex requests quickly, improving their ability to respond to them. Transfer learning speeds up this process, making bots more adaptive to changing customer needs, improving customer service, and increasing operational business efficiency.

Prospects for the development of transfer learning
Transfer learning is now one of the main drivers of machine learning, but what do the numbers say about its real position and possible future?
Growth in industry application
According to a study by Grand View Research, the global machine learning market is valued at $36.73 billion in 2022 and is expected to grow at a compound annual growth rate (CAGR) of 34.8% from 2023 to 2030. This growth is supported by rapid developments in automation, deep learning, and technology applications in various fields such as advertising, healthcare, retail, and finance.
Transfer learning, as an integral part of machine learning, plays a key role in this growth. It allows for reducing time and resources for model development and training, making them more accessible and efficient across various industries. This trend, along with the availability of vast datasets and the creation of more efficient algorithms, leads to innovations in speech recognition, natural language processing, etc.
Integration with other technologies
Transfer learning is not an isolated technology that finds its strength in integrating other advanced technologies. It can be used with cloud computing, the Internet of Things (IoT), and blockchain.
- Cloud computing. Transfer learning can leverage the power of cloud platforms for processing and analyzing large volumes of data, accelerating the learning process and making it more scalable.
- Internet of Things (IoT). In conjunction with IoT, transfer learning can provide smart solutions in areas such as manufacturing, healthcare, and urban infrastructure, and analyze data from multiple devices in real time.
- Blockchain. Integration with blockchain can ensure security and transparency in data processing, which is especially important in the financial and legal spheres.
But transfer learning, like any other advanced technology, is not devoid of ethical and social issues that need to be considered:
- Data privacy. The use of large datasets may raise questions about the privacy and security of personal information. Strict compliance with data protection laws and ethical standards is required.
- Social impact. Implementing transfer learning in various industries may lead to changes in the workforce, requiring retraining and adaptation. This may raise social issues related to employment and education.
- Ethical use. It is necessary to ensure that the technology is used following generally accepted ethical standards, excluding discrimination and inequality in its application.
The prospects for transfer learning are promising, with the potential for significant growth and integration with other cutting-edge technologies. However, responsible development and implementation must consider ethical and social implications to ensure that this technology benefits a wide range of industries without compromising individual rights or societal values.
Promising methods and techniques in transfer learning
Adaptive architectures. Adaptive architectures in transfer learning represent systems capable of changing their structure depending on specific tasks and data.
- Self-organizing networks. These networks can automatically adapt to new data and tasks, optimizing their structure for maximum efficiency.
- Modular systems. Developing modular systems combining different methods, algorithms, and even models allows for incredibly flexible and scalable solutions.
Methods to reduce overfitting. Overfitting is one of the main problems in machine learning, and in transfer learning, it is no exception.
- Regularization using meta-learning. Applying meta-learning to determine optimal regularization parameters can reduce the risk of overfitting.
- Active learning. Using active learning to select the most informative examples can reduce the need for large datasets and also decrease the likelihood of overfitting.
Hybrid models. Hybrid models combine various learning methods and algorithms to achieve better results.
- Combination of supervised and unsupervised learning. Integrating these methods can provide a deeper understanding of the data and improve the model's generalization ability.
- Integration with other machine learning methods. Hybridizing transfer learning with other methods, such as ensemble methods or multi-task learning, can lead to more powerful and robust models.
These new methods and techniques provide future roads for research and application across various industries, supporting the growth and development of the entire field of machine learning.
Best practices using LLM with transfer learning to improve your business
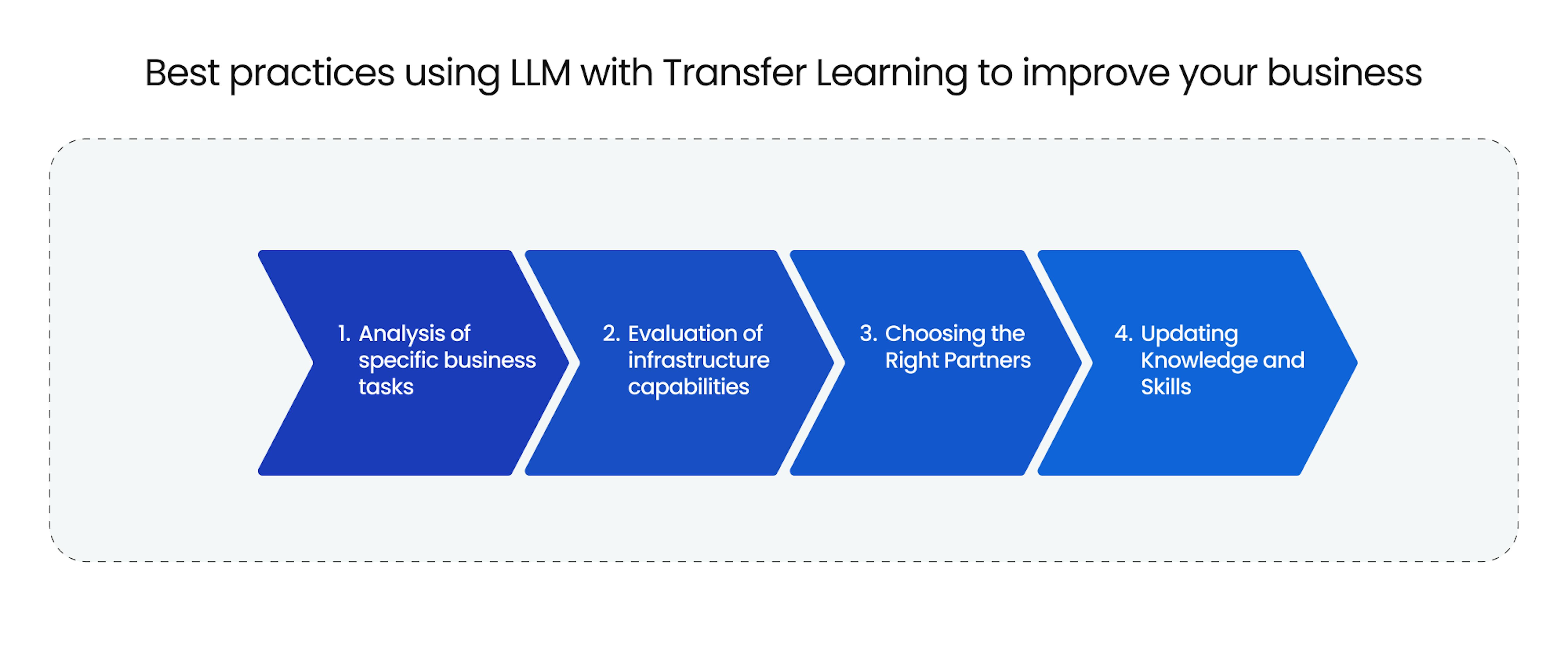
Analysis of specific business tasks. Before applying transfer learning in LLM, it's crucial to define current and future data processing needs clearly. Depending on the automation of customer inquiries, sentiment analysis on social media, or other specific tasks that can be optimized with this technology takes different actions.
Evaluation of infrastructure capabilities. Although transfer learning reduces the resources required to work with LLM, it still demands specific computational power and data storage. Ensure your current infrastructure can support the necessary loads, including potential cloud solutions, to integrate this technology effectively.
Choosing the right partners. Collaborating with leading companies and experts in Machine Learning can ensure successful integration and utilization of transfer learning in LLM. Assess their experience and specialization to find the best match for your needs.
Updating knowledge and skills. It's essential to keep up with new research and practices in transfer learning and LLM. Consider conducting specialized courses and workshops for your team to keep their knowledge up to date.
Summary
In this article, you learned about the development of transfer learning and its role in enhancing machine learning performance, especially in reducing time and resources for training models and increasing their adaptability to new tasks.
Also, you learned about specific examples of applying LLM with transfer learning in business, such as chatbots, automatic translators, recommendation systems, etc. And current trends and prospects, including industry growth, integration with other technologies, and ethical considerations.
Please get in touch with us if you have any questions or need a free consultation on developing AI solutions. We are always ready to provide expert support and assistance in your projects to help your business get ahead.


FAQ
What is the power of large language models (LLMs)?
What is fine-tuning in transfer learning for large language models?
What is LLMOps?
How is transfer learning applied in real-world scenarios?
How does transfer learning shape the future of deep learning
Latest articles here




