


Artificial intelligence is just starting to resemble what science fiction writers described in their works. But this is already enough to open fundamentally new possibilities for us, which are now becoming an integral part of our life. And all these numerous possibilities are backed by various machine learning algorithms, which process data in different ways, depending on which models they were trained.
Today we will dive into semi-supervised learning, how it works, what problems it solves, and what opportunities it provides. But let's remember the difference between supervised and unsupervised learning first.
All this is explained in detail in our article, enjoy a beneficial reading.
What is supervised learning?
Supervised learning is an approach in machine learning where the model is trained based on labeled data, where each input example corresponds to a known correct label. The model uses this to extract patterns and create connections between input data and their corresponding labels in order to learn how to predict them for new, unlabeled input data.

An analogy for supervised learning can be the process of teaching a child. When you teach a child certain skills or concepts, you provide examples and explanations of correct answers. The child generalizes these examples and applies them to new situations. For example, when teaching a child to read, you show them the correct pronunciation of letters and words and explain their correct use in a particular context. Then they apply this knowledge when reading new texts or writing their own.
How does supervised learning work?
In supervised learning, the data is initially divided into training and test sets. The training set is used to adjust the parameters of the model.
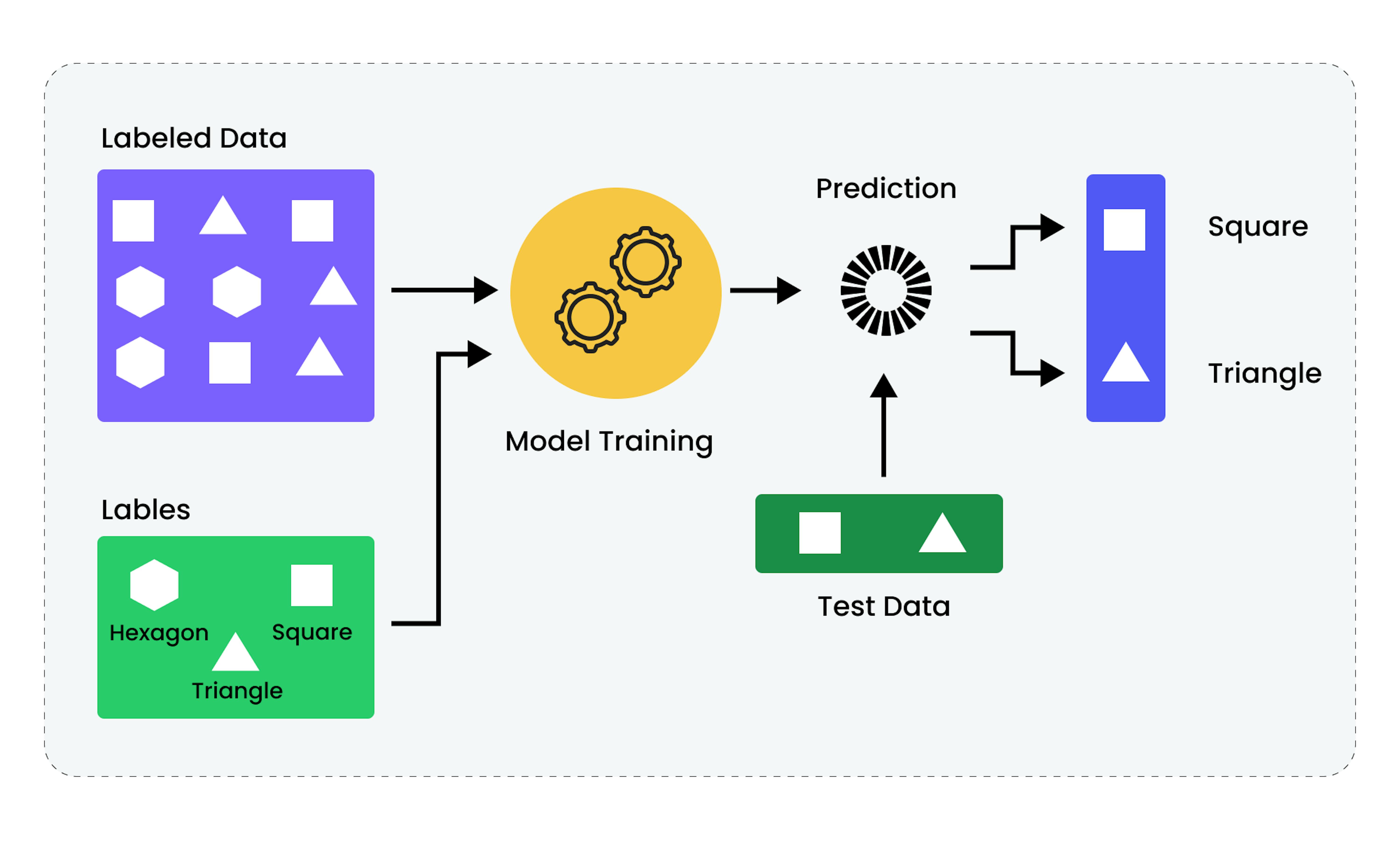
A few different algorithms enable the model to process that data, corresponding to the learning task.
- For classification, the goal is to train the prediction of a category, and there are linear classifiers, decision trees, or logistic regression algorithms. They assign a specific label or class to each input example based on its characteristics.
- For regression, the goal is to predict a quantitative value, and there are linear regression algorithms. They work by predicting a continuous value based on input data. The model adapts its internal parameters during learning to minimize the error between the predicted and actual labels.
Separately, internal parameters are optimized using algorithms such as gradient descent. It iteratively corrects the model's parameters to minimize the loss function, which measures the difference between the model's predictions and the actual values.
After training and optimization, the model is tested on a test dataset, a set of examples that were not used in the learning process, and that serve to check the model's performance on new, previously unseen data. The model receives input data from the test set and makes predictions. These predictions are then compared with the actual labels from the test set. Performance metrics, such as accuracy for classification tasks or mean squared error for regression tasks, are then used to assess how well the model works.
Of course, these are just the main steps of training the models, and there are many other substeps in the field. But it shows the sense of this approach, where the model gets its possibilities by having correct examples in advance.
📖 There are also various machine learning paradigms, one of which is contrastive learning – you can read about in our article "The Power of Contrastive Learning: From Theory to Real-World Applications"
Advantages and limitations of supervised learning
The advantages of this approach seem obvious, but like any approach, it also has disadvantages. Let's look at both.
Advantages
- High model accuracy. Supervised learning provides high prediction accuracy as models are trained on labeled data, allowing them to determine relationships and patterns accurately.
- Performance optimization. It allows for the optimization of model performance, as learning is based on specific target variables, allowing the model to focus on specific aspects of the data.
- Direct prediction. It enables models to make direct predictions, as they are trained based on specific target variables, allowing them to predict specific outcomes based on input data.
Limitations
- Increased time. Supervised learning requires significant time for data labeling, which can slow down the learning process and application of models.
- High cost. Labeling large data sets can be expensive, especially if expert knowledge is required.
- Limited learning. It is limited to the patterns specified in the labels. This means that models may not be able to detect new or unexpected patterns in the data.

What is unsupervised learning?
Unsupervised learning is an approach in machine learning where the model analyzes unlabeled data without explicit correct labels and identifies internal patterns, clusters, or hidden factors that may be present in the data. The goal is to understand the data and determine their structure and relationships between objects and features. It is helpful for further data analysis, decision-making, and supporting other tasks, including supervised learning, based on the discovered patterns and data structures.

Imagine a child in a new environment where everyone speaks a language unfamiliar to them, with no teacher or a dictionary available at the moment. So, they must observe and listen, trying to independently establish connections and understand the rules of this new language.
Initially, the child may pay attention to the tonality and emotion of the voice — perhaps some phrases are pronounced with great excitement, others with pleasure, and some with sadness. After building these initial associations, the child notices the contexts in which these words and phrases are typically used. They begin to understand that certain words and phrases are used only in specific situations or by certain people. This helps to complete their understanding.
How does unsupervised learning work?
In unsupervised learning, the data is usually not divided into training and test sets as explicitly as in supervised learning, as there are no labels for comparison. However, a portion of the data can be set aside for subsequent quality of learning checks.
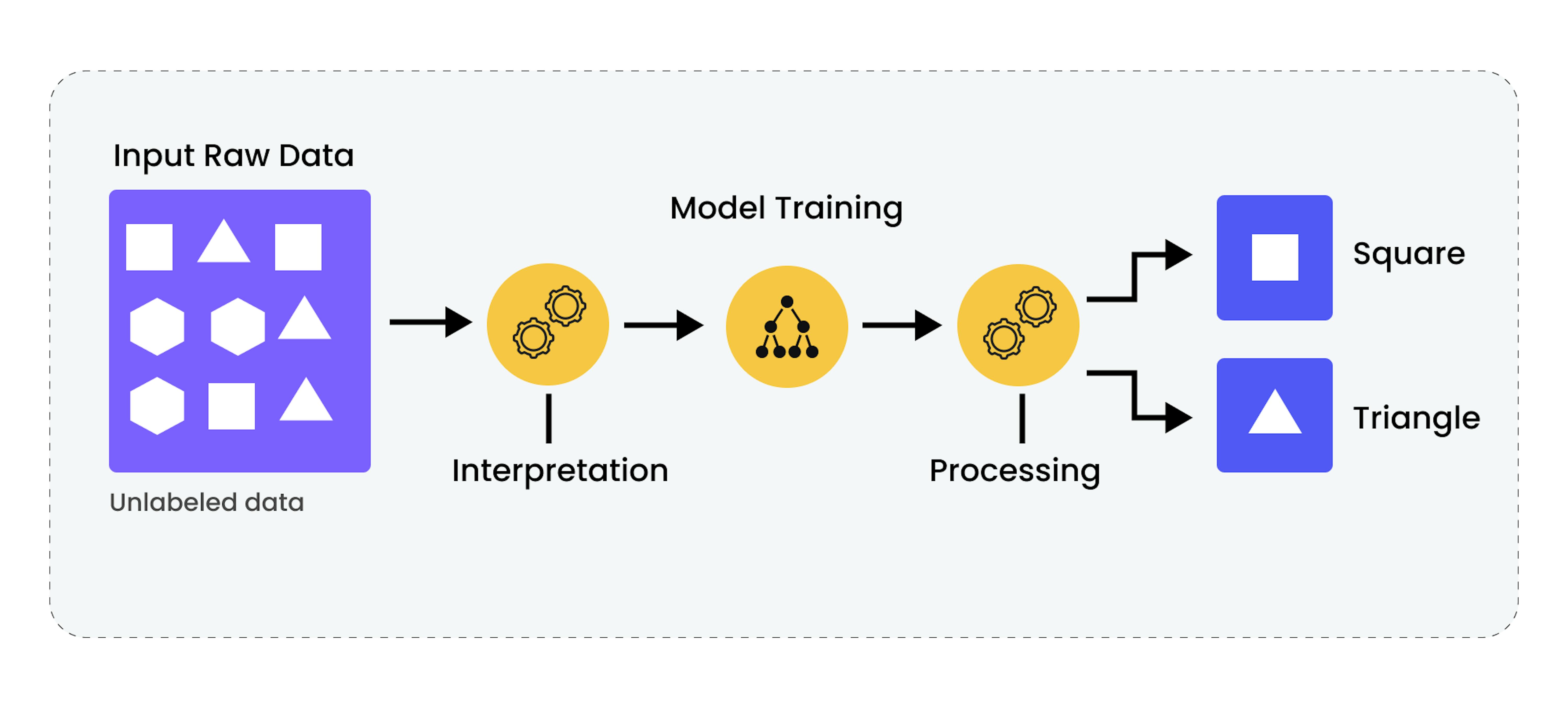
- One method of unsupervised learning is clustering. The goal of clustering is to explore the structure of the data and find groups of similar examples in the data. The K-means algorithm will try to group the data in such a way that the data within one cluster are as similar to each other as possible and the data between different clusters are as different as possible.
- Another method is the search for associative rules. The goal is to find relationships or patterns between individual elements of data. The Apriori algorithm can be used to search for sets of items that are often purchased together.
- A third method is dimensionality reduction. The goal is to simplify the data while retaining the most important information. The Principal Component Analysis (PCA) algorithm can be used to transform a large set of features into a smaller set while retaining the most important information.
After applying one or multiple methods, the set-aside data or new data can be used to check the quality of learning. In clustering, you can check the stability of clusters or use metrics such as the silhouette coefficient to assess the clustering quality.
These were the main training steps, and actually, there are much more of them. But it also shows the sense of this approach, where the models get their possibilities by having unlabeled data, finding the relationships there themselves and often the ones that humans can not find manually.
What are the advantages and limitations of unsupervised learning?
This approach allows you to train a model on unlabeled data and offers many obvious advantages but has limitations. Let's look at them.
Advantages
- Does not require labeled data. Models are trained on unstructured data, simplifying data preparation and making it ideal for large volumes of data.
- Lower costs. The absence of data labeling dramatically reduces the cost of training the model.
- Automatic detection of patterns. Models can automatically detect hidden structures in the data.
Limitations
- Lower accuracy. In some tasks, especially when labeled data is available, accuracy may be lower than with unsupervised learning.
- Limited in prediction. Unsupervised learning is used for research purposes, such as clustering or anomaly detection, and is not intended for prediction.
In conclusion, unsupervised learning is a powerful tool for data analysis, instrumental when working with large data sets where labeling may be impractical or costly.
Semi-supervised learning explained
Semi-supervised learning is a machine learning technique that uses a combination of supervised and unsupervised learning by applying labeled and unlabeled data to train a model.
Labeled data provides the model with explicit examples of what input data corresponds to which labels, allowing the model to learn to predict it for new data. Unlabeled data is then used to refine and improve this model, helping it better understand its overall structure and distribution, which can lead to more accurate and generalized predictions when dealing with new, unlabeled data. In particular, unlabeled data can be used to improve the model's generalization ability, refine decision boundaries in classification tasks, and utilize structural information contained in the data. This is very useful when there is little labeled data but a lot of unlabeled data.
How does semi-supervised learning work?
Semi-supervised learning is now the subject of active research and experimentation. It has several strands within it. Here are the main ones.
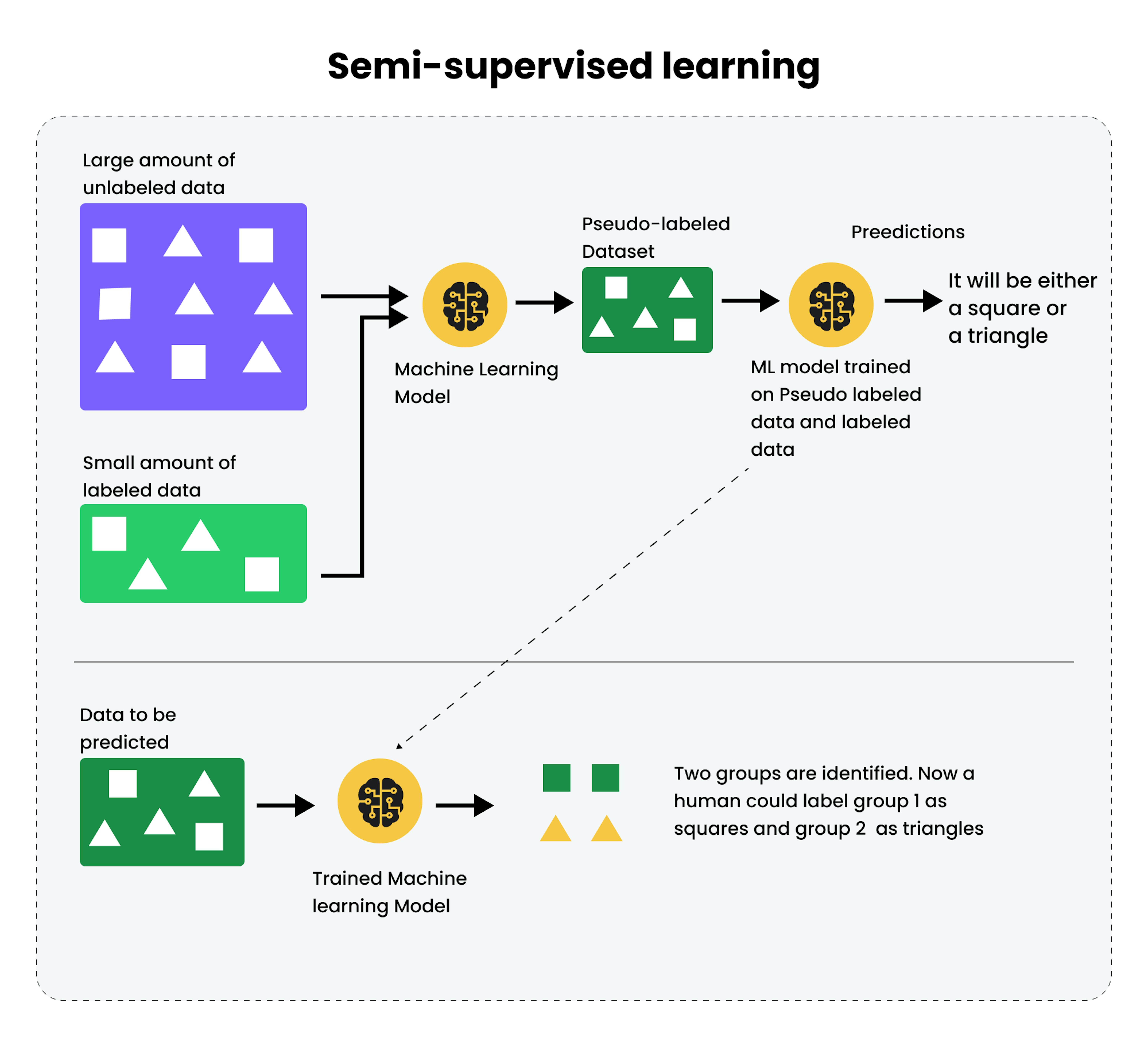
- Self-training
Self-training is an approach where the model is first trained on labeled data and then used to generate labels for unlabeled data. These generated labels are then added to the training dataset, and the training process is repeated. This process is iterative and continues until a certain degree of confidence in the model's predictions is reached, or a specified number of iterations have been performed. - Co-training
Co-training is an approach where two models are used, each trained on a subset of the features of the original dataset. After training, each model is used to generate labels for unlabeled data, which are then added to the training dataset of the other model. This process is also repeated iteratively. Co-training is based on the assumption that different models can learn from different aspects of the data and together they can better generalize the unlabeled data. - Multi-view training
Multi-view training is a variation of co-training, where each model is trained on its unique data representation. This can be particularly useful when you have different types of data, such as text and images, that can be used to predict the same label. - SSL using Graph Models
In this approach, the data is presented in a graph, where nodes represent data examples, and edges represent the similarity between examples. Data labels are then propagated through the graph to unlabeled data. This can be particularly useful when the data has a complex structure that can be better represented as a graph.

Semi-supervised learning advantages
Even though semi-supervised training is still undergoing active development and is changing rapidly, it already solves many problems and has advantages over supervised and unsupervised training.
- Improved generalization. Semi-supervised learning allows the model to extract more information from labeled and unlabeled data and better understand the overall structure. This can lead to more accurate and robust predictions, even where labeled data is limited.
- Cost optimization for labeling. Labeling data requires significant resources, both time and money. Semi-supervised learning can reduce these costs by allowing the model to learn from unlabeled data while still enabling labeled data.
- Flexibility and robustness. It provides flexibility in using different data types from different data sources, allowing models to adapt to various learning scenarios and be more robust to changes in the data distribution.
- Improved clustering quality. It can improve clustering quality by using unlabeled data to refine the boundaries between clusters.
- Handling rare classes. It can be useful when dealing with rare classes when only a small number of labeled examples of these classes are available. This can help the model generalize these rare classes better, improving its classification task performance.
- Combining prediction and discovery capabilities. Semi-supervised learning can combine prediction and discovery capabilities, improving performance in various tasks, from market analyses and predictions to anomaly detection or novelty detection.
Semi-supervised learning limitations
Even though semi-supervised training combines the best advantages of previous approaches and solves many of the problems inherent in them, it also has its limitations.
- The complexity of choosing architecture and parameters. Choosing a suitable model architecture and tuning parameters can be complex in semi-supervised learning. This may require more time and resources for experimentation and optimization.
- Noise in data. Unlabeled data may contain noise or be irrelevant to the task, negatively impacting the model's performance. This can lead to overfitting on noisy or irrelevant data, degrading the model's generalization ability.
- Consistency error. Semi-supervised learning often relies on the consistency assumption, which states that close examples in feature space should have the same labels. However, this assumption can be violated in real-world data, leading to errors. For example, in the presence of outliers or noise in the data, label consistency can be violated.
- Computational complexity. It can be computationally hard, especially when using complex models or large volumes of data. This may require more computational resources and time to train models, which can be problematic in real-world conditions where resources and time may be limited.
- Uncertainty in performance evaluation. Evaluating the performance of a semi-supervised learning model can be complex, as it depends on the quality of the unlabeled data and how the model uses it.
When to use semi-supervised learning
All of the above advantages give many reasons to use semi-supervised learning, where supervised learning is not very profitable, and unsupervised training is not possible.
- Limited resources for labeling. Suppose the process of labeling data requires significant time or financial costs, for example, medical images that need to be labeled by qualified specialists. In that case, semi-supervised learning can be an effective solution. It allows unlabeled data to improve the model, reducing labeling costs.
- A large volume of unlabeled data. In some fields, such as social networks or the internet, a huge amount of unlabeled data is available. Semi-supervised learning can use this data to improve models, even if only a small amount of labeled data is available.
- Working with unstructured data. Semi-supervised learning can be useful for unstructured data like texts, images, or sounds. These data can be difficult to label, but semi-supervised learning can use unlabeled data to improve understanding of these data and improve models.
- Rare classes. Labeled examples of rare classes may be limited in some classification tasks, such as fraud detection or rare diseases. In these cases, semi-supervised learning can help improve the detection of these classes by using unlabeled data.
When not to use semi-supervised learning
There is no such thing as a silver bullet, so even training with semi-supervised learning can be more or less successful to use.
- High level of noise in unlabeled data. If unlabeled data contains a lot of noise, such as errors in the data or irrelevant examples, this will negatively impact the learning of the model and lead to incorrect predictions.
- High computational costs. Some semi-supervised learning methods can be computationally complex, especially when working with large volumes of unstructured data. If computational resources are limited, it may be preferable to use other learning methods.
- Heterogeneity of data. If the data is very heterogeneous or has a too complex structure, semi-supervised learning may be ineffective. For example, if the data contains many different classes that are difficult to separate or if the class distributions overlap significantly, semi-supervised learning may not be able to use unlabeled data to improve the model's performance effectively.
Semi-supervised learning applications
Now let's outline the main opportunities offered by this method of teaching. Some of them were created by supervised and unsupervised learning and greatly improved by semi-supervised learning, while others were unlocked specifically by semi-supervised learning.
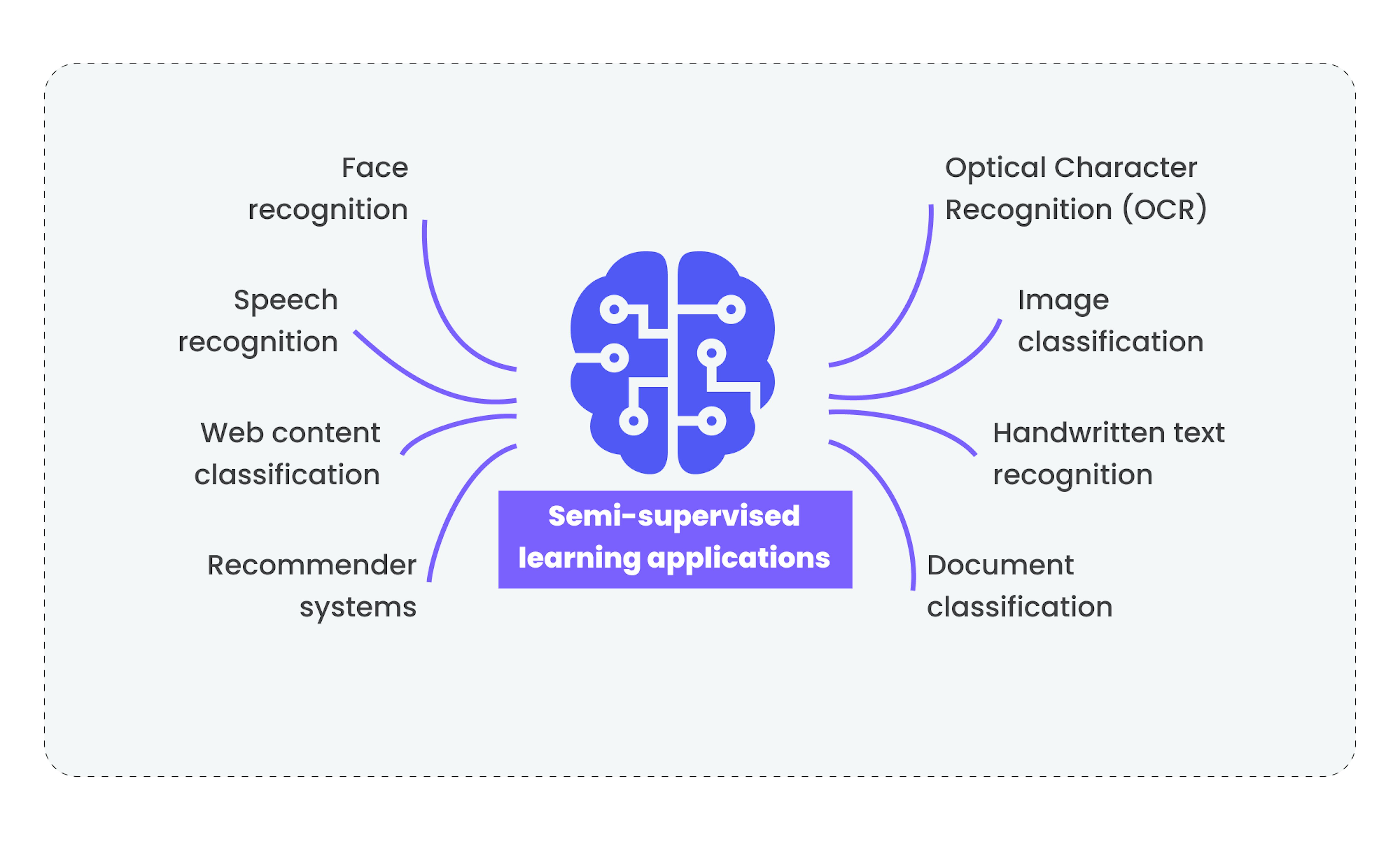
- Face recognition. Semi-supervised learning enables models to identify and analyze complex facial features such as eye shape, skin texture, and facial contours, improving identification accuracy by using Graph Convolutional Networks (GCN) algorithms that can handle structured data like graphs.
- Handwritten text recognition. It allows models to adapt to different styles of handwritten text, improving their ability to recognize and interpret different variants of letter and word writing by using methods like Variational Autoencoders (VAE) that can generate new data samples based on learned features.
- Speech recognition. It enables models to adapt to different accents, speech rates, and intonations, improving their ability to recognize speech under various conditions. It also uses Convolutional Neural Networks (CNN) to extract temporal and frequency features from audio data.
- Web content classification. Semi-supervised learning allows models to learn from large volumes of unlabeled data from the internet. It improves their ability to classify web content into various categories using algorithms like Topic modeling that allows the model to extract topics from large volumes of text data.
- Recommender systems. It can perform better recommender systems by allowing models to learn from many unlabeled data about user preferences, improving their ability to offer relevant recommendations. It uses algorithms like Matrix factorization that enable the model to learn hidden user preferences based on their past behavior.
- Document classification. It improves the model's ability to classify documents into various topics and categories by algorithms like Latent Dirichlet Allocation (LDA), which allows the model to extract topics from large volumes of text data.
- Image classification. Semi-supervised learning allows models to learn from large volumes of unlabeled images, improving their ability to classify images into various categories and objects. This also became possible through CNN, which can extract spatial and texture features from images.
- Optical Character Recognition (OCR). It enables models to recognize and interpret different styles and forms of writing, improving their ability to recognize text in images and documents also by CNN that can extract spatial and texture features from text images.
Semi-supervised learning examples
Those companies that implement machine learning in their processes are way ahead of their competitors. And those using advanced machine learning methods are moving even further ahead. Let's look at use cases in the context of primary industries and large companies.
Security
Companies like Google use semi-supervised learning for anomaly detection in network traffic. While using large volumes of data about normal network traffic, machine learning models are trained to recognize common patterns. They then use this knowledge to detect deviations that may indicate potential security threats. Besides anomaly detection in network traffic, it is useful for malware detection, user behavior analysis to detect suspicious activity, and even for detecting physical threats such as unauthorized access to secured areas.
Finance
Companies like PayPal use it for fraud detection in financial transactions. Machine learning models are trained based on a large number of transactions to recognize repetitive patterns and identify deviations that may indicate fraudulent actions. Moreover, semi-supervised learning can help predict company bankruptcies, market trend analysis for optimizing investment strategies, and even automate the creditworthiness assessment process of clients.
Medical diagnostics
Companies like Zebra Medical Vision use semi-supervised learning for symptom detection in medical diagnostics. Models are trained based on a large amount of medical data to recognize typical patterns and identify deviations that may indicate the presence of a disease. Besides symptom detection, semi-supervised learning can be used for disease progression prediction, medical image analysis for pathology detection, and even for creating personalized treatment plans based on the analysis of multiple sets of medical data.
Bioinformatics
Companies like Google DeepMind use it for protein structure prediction. Models are trained based on data about protein structures to recognize typical patterns and indicate the presence of a disease. Also, it can help in genomic data analysis for disease genetic marker detection, protein interaction prediction, and even in creating species evolution models based on genetic data analysis.
Robotics
Companies like Boston Dynamics use it for robot navigation training. Models are trained based on data about movement and environmental interaction to recognize typical patterns and adapt to changing conditions. Besides navigation training, it's good for training complex manipulations, such as assembling parts or performing surgical operations.
Geology
Companies like Chevron analyze geological data to detect potential mineral or oil deposits. Models trained based on this geological data can recognize typical patterns and may indicate the presence of valuable promises. Besides deposit search, it helps with seismic activity prediction, soil composition analysis for agriculture, and even for the creation of 3D underground structure models based on geophysical data.
Summary
The complexity and cost of training machine learning models today are significant barriers for many companies, so staying abreast of the latest training methods that reduce cost and increase training efficiency is critically important.
Now you better understand how supervised and unsupervised learning methods work, and comprehend the combination of them is semi-supervised learning. Each approach is incredibly good for different tasks, because of its advantages and limitations. Semi-supervised learning takes the best of both methods and solves many of their problems. However, it also has its limitations, which are actively being addressed in ongoing developments.
And if you need to implement or develop machine learning models for optimizing and automating your business or even creating an entire product, but you still have questions about which approach to choose and how to implement it most profitably — contact our experts for a free consultation. We will carefully review your case and offer you the most beneficial and effective solution.


Latest articles here




